
File:WineHQ ratings.svg

Size of this PNG preview of this SVG file: 800 × 400 pixels. Other resolutions: 320 × 160 pixels | 640 × 320 pixels | 1,024 × 512 pixels | 1,280 × 640 pixels | 2,560 × 1,280 pixels.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Original file (SVG file, nominally 800 × 400 pixels, file size: 396 KB)
Captions
Captions
Add a one-line explanation of what this file represents
Summary
[edit]{kind=link}
| Description |
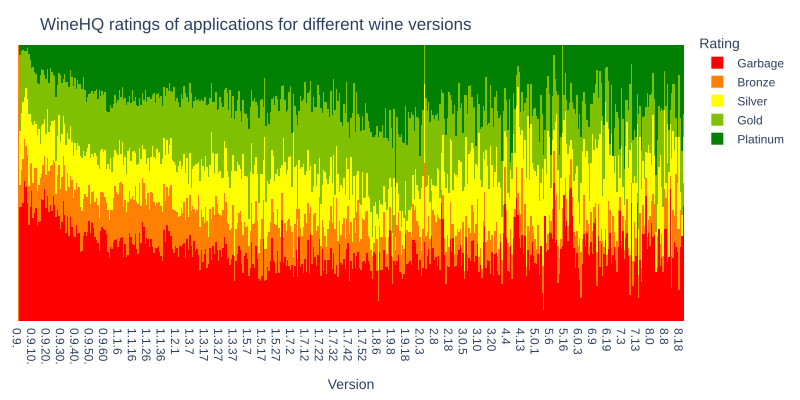
Deutsch: WineHQ ratings of applications for different wine versions |
| Date | |
| Source | Own work |
| Author | Laserlicht |
Licensing
[edit]{kind=link}
I, the copyright holder of this work, hereby publish it under the following license:
| This file is made available under the Creative Commons CC0 1.0 Universal Public Domain Dedication. | |
| The person who associated a work with this deed has dedicated the work to the public domain by waiving all of their rights to the work worldwide under copyright law, including all related and neighboring rights, to the extent allowed by law. You can copy, modify, distribute and perform the work, even for commercial purposes, all without asking permission.
|
Code to create chart
[edit]{kind=link}
Execute in Jupyter Notebook. There is sequential execute possible. If something aborts it's possible to resume. Data is written as pickle file for further analysis. Script needs very long to execute (> 5h).
Needs pip librarys: beautifulsoup plotly pandas numpy natsort
import urllib.request
import re
from bs4 import BeautifulSoup
import plotly.express as px
import pandas as pd
import numpy as np
import pickle
import os
from natsort import natsorted, natsort_keygen, ns
url = "https://appdb.winehq.org/objectManager.php?bIsQueue=false&bIsRejected=false&sClass=application&sTitle=Browse+Applications&iItemsPerPage=200&sOrderBy=appName&bAscending=true&sOrderBy=appId&bAscending=true&iPage="
url_version = "https://appdb.winehq.org/objectManager.php?sClass=application&iId="
#
# get pages
#
req = urllib.request.Request(
url + "1",
data=None,
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
}
)
f = urllib.request.urlopen(req)
html = f.read().decode('utf-8')
pages = int(re.search(r'of <b>(\d*)<\/b>', html, re.IGNORECASE).group(1))
pages
#
# get applications
#
applications = None
for i in range(pages):
req = urllib.request.Request(
url + str(i+1),
data=None,
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
}
)
f = urllib.request.urlopen(req)
html = f.read().decode('utf-8')
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", {"class": "whq-table"})
if isinstance(applications, pd.DataFrame):
applications = pd.concat([applications, pd.read_html(table.prettify())[0]])
else:
applications = pd.read_html(table.prettify())[0]
pickle.dump(applications, open("wine_applications.pickle", "wb"))
applications
if os.path.isfile("wine_applications.pickle"):
applications = pickle.load(open("wine_applications.pickle", "rb"))
applications_to_process = applications.iloc[:, 1].values.tolist()
versions = None
#
# get versions
#
if os.path.isfile("wine_versions.pickle"):
applications_to_process, versions = pickle.load(open("wine_versions.pickle", "rb"))
while len(applications_to_process) > 0:
req = urllib.request.Request(
url_version + str(applications_to_process[0]),
data=None,
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
}
)
f = urllib.request.urlopen(req)
html = f.read().decode('utf-8')
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", {"class": "whq-table"})
if table != None:
df = pd.read_html(table.prettify(), extract_links="body")[0]
df["AppId"] = applications_to_process[0]
if isinstance(versions, pd.DataFrame):
versions = pd.concat([versions, df])
else:
versions = df
applications_to_process.remove(applications_to_process[0])
pickle.dump((applications_to_process, versions), open("wine_versions.pickle", "wb"))
print("remain: " + str(len(applications_to_process)))
versions_to_process = []
for i in range(versions.shape[0]):
versions_to_process.append((versions["Version"].tolist()[i][0], versions["Version"].tolist()[i][1], versions["AppId"].tolist()[i]))
tests = None
#
# get tests
#
if os.path.isfile("wine_tests.pickle"):
versions_to_process, tests = pickle.load(open("wine_tests.pickle", "rb"))
while len(versions_to_process) > 0:
req = urllib.request.Request(
versions_to_process[0][1] + "&bShowAll=true",
data=None,
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
}
)
f = urllib.request.urlopen(req)
html = f.read().decode('utf-8')
soup = BeautifulSoup(html, "html.parser")
table = soup.find("div", id="collapse-tests").find("table", {"class": "whq-table"})
if table != None:
df = pd.read_html(table.prettify(), extract_links="body")[0]
df["Ver"] = versions_to_process[0][0]
df["AppId"] = versions_to_process[0][2]
if isinstance(tests, pd.DataFrame):
tests = pd.concat([tests, df])
else:
tests = df
versions_to_process.remove(versions_to_process[0])
pickle.dump((versions_to_process, tests), open("wine_tests.pickle", "wb"))
print("remain: " + str(len(versions_to_process)))
if os.path.isfile("wine_applications.pickle"):
applications = pickle.load(open("wine_applications.pickle", "rb"))
if os.path.isfile("wine_versions.pickle"):
applications_to_process, versions = pickle.load(open("wine_versions.pickle", "rb"))
if os.path.isfile("wine_tests.pickle"):
versions_to_process, tests = pickle.load(open("wine_tests.pickle", "rb"))
version_no = natsorted([x for x, y in tests["Wine version"].drop_duplicates().tolist() if not "staging" in x and not "rc" in x], alg=ns.IGNORECASE)
version_no
df = pd.DataFrame({"version": version_no})
df
tests_edit = tests.copy()
tests_edit["Wine version"] = [x for x, y in tests_edit["Wine version"]]
tests_edit["Test date"] = [x for x, y in tests_edit["Test date"]]
tests_edit["Rating"] = [x for x, y in tests_edit["Rating"]]
tests_edit
df1 = pd.merge(df, tests_edit, how="left", left_on="version", right_on="Wine version")
df1 = df1[["version", "Test date", "Rating"]]
df1
df2 = pd.pivot_table(df1, index="version", columns="Rating", values="Rating", aggfunc="count").reset_index()
df2 = df2.fillna(0)
df2["Sum"] = df2["Bronze"] + df2["Garbage"] + df2["Gold"] + df2["Platinum"] + df2["Silver"]
df2["Bronze %"] = df2["Bronze"] / df2["Sum"]
df2["Garbage %"] = df2["Garbage"] / df2["Sum"]
df2["Gold %"] = df2["Gold"] / df2["Sum"]
df2["Platinum %"] = df2["Platinum"] / df2["Sum"]
df2["Silver %"] = df2["Silver"] / df2["Sum"]
df2 = df2.replace([np.inf, -np.inf], 0)
df2
df3 = df2.copy()
df3 = df3[["version", "Bronze %", "Garbage %", "Gold %", "Platinum %", "Silver %"]]
df3 = pd.melt(df3, id_vars="version", value_vars=list(df3.columns[1:]))
df3['Rating'] = df3['Rating'].str.replace(' %','')
df3['order'] = df3['Rating'].replace({'Garbage':0, 'Bronze':1, 'Silver':2, 'Gold':3, 'Platinum':4})
df3
fig = px.bar(df3.sort_values(["version", "order"], key=natsort_keygen()), width=800, height=400, x="version", y="value", color="Rating", color_discrete_map={"Garbage": 'rgb(255, 0, 0)', "Bronze": 'rgb(255, 128, 2)', "Silver": 'rgb(255, 255, 0)', "Gold": 'rgb(128, 192, 0)', "Platinum": 'rgb(0, 128, 0)'})
fig.update_layout(bargap=0)
fig.update_layout({
'plot_bgcolor': 'rgba(0, 0, 0, 0)',
'paper_bgcolor': 'rgba(255, 255, 255, 255)',
'title': dict(text = 'WineHQ ratings of applications for different wine versions', y=0.955),
'margin': dict( l = 10, r = 10, b = 10, t = 30)
})
fig.update_traces(marker_line_width=0)
fig.update_yaxes(visible=False, showticklabels=False)
fig.update_xaxes(title='Version')
fig.write_image("wine.svg")
fig.show()
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 13:26, 25 November 2023 | | 800 × 400 (396 KB) | Laserlicht (talk | contribs) | Uploaded own work with UploadWizard |
You cannot overwrite this file.
File usage on Commons
The following page uses this file:
File usage on other wikis
The following other wikis use this file:
- Usage on de.wikipedia.org
- Usage on en.wikipedia.org
{kind=link}